
The experimental document classifier is based on the vector space model. Documents are placed in an n-dimensional space where the dimensions are defined by the unique words (or wordpairs or wordtriplets) in the collection. By calculating the direction of each document from the origin O (normalizing their dot-products using the Euclidian norm), the similarity between two documents is defined as the cosine of the angle between the documents in the n-space (Fig. 1). It follows that two orthogonal documents (that share no common terms) receive a cosine of zero and that identical documents receive a cosine of one.
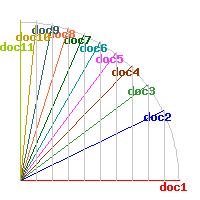
Fig. 1. A query (doc1) and it's similarity to each of the documents of a collection
(doc2-doc11)
Fig. 1 depicts a theoretical situation where the similarity of a query (doc1) to ten other documents (doc2-doc11) is defined by the values 0.9, 0.8, 0.7 .... 0.0. The figure does not depict the mutual closeness of the other documents (by analogy: though we measure to distance from Paris to London to 320 km. and the distance from Paris to Strasbourg to 400 km. we cannot conclude that e.g. the distance from London to Strasbourg is 80 km.!). For this reason, the online classifier generates one picture similar to Fig. 1 for each of the uploaded documents and all distances are depicted in a distance matrix.
Based on the distance matrix the classifier performs an agglomerative hierarchical clustering where each document is placed in separate clusters that successivly are merged till only two clusters remain. Normally such clustering is stopped when either a certain predefined number of clusters or a certain threshold of disimilarity between clusters is achieved. In case of the classifier users are simply encouraged to disregard any further clustering that does not make sense in the context they are exploring.
Settings: The classifier supports the common idf (inverse document frequency) weighting scheme: Frequent terms (words) occurring in few documents are weighted high. The idf-weighting scheme has to some extend the same effect as a stop list, i.e. a list of very common and general words to ignore (words like "and", "it", "the", etc. occuring in almost all documents).
Additionally, stemming can be applied, i.e. various morphological forms of the same word like "walks, walked, walking" are replaced by their stem "walk". This option should only be used on English documents. Stemming reduces the number of terms in the n-space. To explore the stemmer alone, click here.
Finally, the terms can be defined as either words, word pairs, or word triplets. The longer units are useful especially when the task is to find an authors "fingerprints" in documents. However, they also drastically increase the number of dimensions in the n-space. This option should be chosen with care. Since the online classifier runs on a remote Apache server, it is terminated if it cannot finalize the execution within a limit number of seconds (currently 60 sec.).